6.2 CLIENT SERVER MODEL, HTTP
![]()
INTRODUCTION |
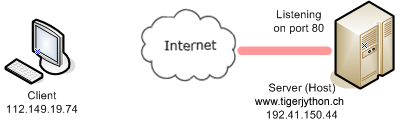
You should already know that a web page displayed in your web browser is described by an ordinary HTML text file, which is typically located on an Internet server (also called a host). In order to locate the file, the browser uses the URL in the form http://servername/filepath.
|
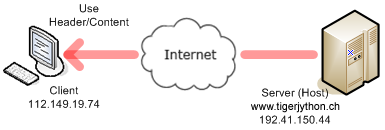
REQUESTING A WEBSITE WITH HTTP |
|
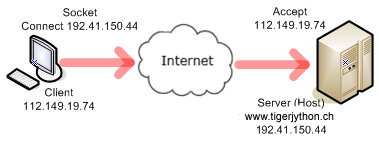
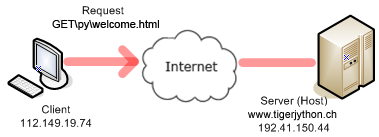
Your client program performs the phases 1, 2, and 4 and fetches the file welcomex.html located in the subdirectory py of the server document path. The method socket() of the socket class provides a socket object to the variable s. Two constants must be passed that define the correct socket type.
import socket host = "www.tigerjython.ch" port = 80 # Phase 1 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((host , port)) # Phase 2 request = "GET /py/welcome.html HTTP/1.1\r\nHost: " + host + "\r\n\r\n" s.sendall(request) # Phase 4 reply = s.recv(4096) print("\nReply:\n") print(reply) |
MEMO |
|
The request for a website from a web server uses the HTTP protocol. This is an agreement between the client and the server and it determines the procedure of the data transfer in full detail. The GET command is documented in the HTTP as follows [more.. Internet protocols are described in so-called RFC (Request for Comments), HTTP in RFC 2616]:
|
USING HTTPS |
Instead of HTTP, more and more websites require the HTTPS protocol, where the data is encrypted using SSL (Secure Socket Layer). For such a server, an HTTP request on port 80 could result in an error message, as in the following program for the server github.com: import socket host = "www.github.com" port = 80 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((host , port)) request = "GET /py/welcome.html HTTP/1.1\r\nHost: " + host + "\r\n\r\n" s.sendall(request) reply = s.recv(4096) print("\nReply:\n") print(reply) The reply is: HTTP/1.1 301 Moved Permanently Content-length: 0 Location: https://www.github.com/py/welcome.html But it is very easy to change the request to HTTPS. To do this, set the port to 443 and insert a line with ssl.wrap_socket (). import socket import ssl host = "github.com" port = 443 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((host , port)) s = ssl.wrap_socket(s) request = "GET / HTTP/1.1\r\nHost: " + host + "\r\n\r\n" s.sendall(request) reply = s.recv(4096) print("\nReply:\n") print(reply) |
HTTP HEADER AND CONNECT |
|
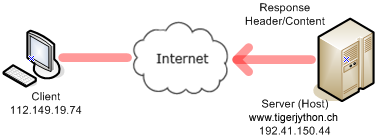
The response consists of a header with status information and the content with the requested file. In order to represent the website, you cut off the header and deliver the contents to a HtmlPane. import socket from ch.aplu.util import HtmlPane host = "www.tigerjython.ch" port = 80 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((host , port)) request = "GET /py/welcome.html HTTP/1.1\r\nHost: " + host + "\r\n\r\n" s.sendall(request) reply = s.recv(4096) index = reply.find("<html") html = reply[index:] pane = HtmlPane() pane.insertText(html) |
MEMO |
|
The function recv(4096) returns maximum 4096 characters from a data buffer, in To cut away the header use the string method find(str), which searches the string for the given substring str and returns the index of the first occurrence. (If the substring is not found, -1 is returned.) Afterwards you can neatly filter out the substring with a slice operation, starting at the index and going to the end. |
READING THE WEATHER FORECASTS |
|
You will probably wonder why you should apply such a complicated procedure to display a web page, when you can do the same thing using a single line insertUrl() from HtmlPane. What you have just learned makes perfect sense, however, if you do not want to display the content of the website in a browser window, for example, but if you are rather interested in only certain information embedded there. As a sensible application your program fetches the current weather forecast from the website of Australian's Bureau of Meteorology and writes it out as text. You can make your life as a programmer even easier, if you use the library urllib2 instead of the socket class to fetch the file from the web server [more... A library often creates a simplistic application-layer over complicated code.Computer scientists talk of high-level abstraction of the underlying low-level code]. To find out where the desired information is located, you can create an analysis program that simultaneously represents the page as a text in the console window and as a web page in your default browser. import urllib2 from ch.aplu.util import HtmlPane url = "http://www.weatherzone.com.au" HtmlPane.browse(url) html = urllib2.urlopen(url).read() print html |
MEMO |
|
The use of software libraries such as urllib2 simplifies the code, but obscures the basic mechanisms. |
PARSING OF TEXTS |
|
You now have the interesting and challenging task of fetching the relevant information from a long string of text, which is the parsing of a text. At first you have the subtask of removing all HTML tags from the string with the function remove_html_tags()The procedure is typical and the applied algorithm can be described as follows: You go through the text character by character. You thereby imagine that you remember two states: you are either inside or outside of a HTML tag. You should only copy the character to the end of an output string if you are outside of a HTML tag. The change of state takes place while reading the tag angle brackets < or >.To extract the information of interest you analyze the text after removing the HTML tags by copying it into a text editor and looking for a token that is unique for the beginning of the information. With the string method find(), you can get the index start of this token. You then look for a token that characterizes the end of the information and search its index end beginning at the start index. For this website the start token is "National Summary" and the end token is "State Weather". The text in between is extracted by a slice operation [start:end]. import urllib2 def remove_html_tags(s): inTag = False out = "" for c in s: if c == '<': inTag = True elif c == '>': inTag = False elif not inTag: out = out + c return out url = "http://www.weatherzone.com.au" html = urllib2.urlopen(url).read() html = remove_html_tags(html) start = html.find("National Summary") end = html.find("State Weather", start) html = html[start:end].strip() print html |
MEMO |
|
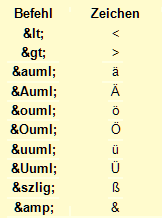
The parsing of texts is usually done character by character. In many cases, however, methods of the string class may help as well [more...Advanced programmers often use the theory of regular expressions (regex)]. In HTML, umlauts and certain special characters are encoded by a sequence initiated with the & sign, according to the following table:
|
VOICE/SPEECH SYNTHESIS OF WEATHER FORECASTS |
|
With your knowledge from the previous chapter Sound, you can have the text of the weather forecast read by a synthetic voice with just a few extra lines of code. You can simply add the following lines to the program: from soundsystem import * initTTS() selectVoice("german-man") sound = generateVoice(html) openSoundPlayer(sound) play() |
EXERCISES |
|