![]()
INTRODUCTION |
Comme c’est le cas dans de nombreux langages de programmation, le langage Python recèle quelques points délicats auxquels même les programmeurs expérimentés ont à faire face. Vous pouvez vous aussi être en mesure de gérer ces difficultés si vous avez conscience qu’ils peuvent constituer une source de danger potentiel. |
LE MODÈLE MÉMOIRE EN PYTHON |
Dans le chapitre 2.6, nous avons abordé les variables en se les représentant comme des boîtes dans lesquelles on peut stocker des valeurs comme des nombres. En gros, cette représentation laisse pour le moment entendre que lors d’une définition de variable telle que a = 2, Python va réserver un espace dans la mémoire vive semblable à une boîte dans lequel le nombre 2 sera stocké. La variable a joue alors le rôle de symbole que l’on utilise à la place de la valeur 2. Cette représentation est bien pratique pour aborder les variables mais il faut savoir qu’elle est limitée et peut conduire à une compréhension erronée du programme car elle n’est pas vraiment correcte et ne rend pas compte de ce qui se passe réellement. Cela vient de ce que toutes les données, en particulier les nombres, sont considérées par Python comme des objets. Les objets sont des structures complexes qui sont bien plus que juste une valeur. Les objets présentent par exemple également des comportements (fonctions, méthodes). Les nombres entiers (objets de type int) « savent » ainsi comment s’additionner entre eux. Voici quelques lignes qui montrent le bien-fondé de cette affirmation:
Ainsi, chaque objet possède une identité (identifiant) unique qui peut être interrogé par la fonction intégrée id():
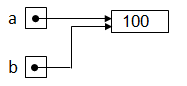
Il faut donc bien comprendre qu’en Python, lorsque l’on définit une variable a, ce nom a n’est rien d’autre qu’un nom qui fait référence à un objet de type int se trouvant en mémoire à l’emplacement mémoire (adresse) 0x2. On dit parfois que a est un alias (dans d’autres langages de programmation, on parle de référence ou de pointeur). Voici comment se représenter la situation de manière visuelle: La différence avec la métaphore de la boîte utilisée jusqu’à présent apparaît avec l’affectation suivante :
La métaphore de la boîte pourrait laisser penser qu’après cette affectation, la mémoire contient deux boîtes différentes contenant toutes deux la valeur 100. En réalité, il n’en est rien : b est juste un deuxième alias faisant référence au même objet mémoire que a, ce qui confirme la fonction id() :
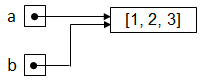
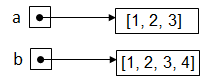
Visuellement, la situation est donc la suivante en mémoire: Ce modèle mémoire orienté objet est d’une très grande importance lorsque le programme ne se contente pas d’utiliser des nombres mais qu’il fait un usage abondant de types de données structurées complexes telles que les listes. Pour s’en convaincre, commençons par définir une première liste a ainsi qu’un deuxième liste b faisant référence au même objet suite à une affectation:
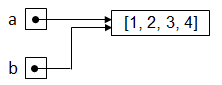
Comme le laisse entendre notre nouveau modèle mémoire, la situation est la suivante: Ainsi, si l’on modifie la liste au travers de l’alias b
la situation en mémoire sera la suivante: Il n’est donc pas étonnant que la liste référencée par l’alias a ait également changé!
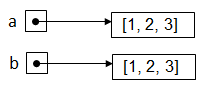
Cette interdépendance des variables a et b peut conduire à d’innombrables erreurs de programmation très subtiles et souvent très difficiles à identifier. Cette interdépendance n’intervient cependant pas lorsque b est nouvellement définie comme une liste séparée car Python génère dans ce cas une nouvelle liste totalement indépendante:
Visuellement, cela produit la situation suivante en mémoire: ce qui permet de modifier la liste b sans affecter la liste a:
puisque l’on aura alors la situation suivante en mémoire: On peut vérifier cette affirmation avec le code suivant:
Cette interdépendance entre les deux variables a et b n’est pas perceptible lorsque l’on utilise des nombres entiers. En effet, lors de l’affectation d’une nouvelle valeur 200 à la variable b, un nouvel objet est créé en mémoire. L’alias b, qui pointait vers le même entier 100 que a après la deuxième instruction b = a, pointe sur le nouvel objet entier 200 après la troisième instruction.
Contrairement à l’idée que favorise la métaphore de la boîte utilisée jusqu’à présent pour se représenter le fonctionnement des variables, l’affectation d’une variable à une autre ne réalise pas de copie de la valeur. Le code suivant montre encore une fois à quel point l’affectation à une nouvelle variable d’une liste contenant des chaines de caractères est problématique. En effet, l’affectation ne copie pas du tout le contenu de la liste:
On peut donc retenir la règle suivante:
Si l’on veut réaliser une véritable copie indépendante d’une liste, à savoir un clone, il y a essentiellement deux solutions à disposition. La première consiste à copier explicitement chaque élément de la liste d’origine dans une autre liste à l’aide d’un code « maison ». La deuxième consiste à utiliser la fonction deepcopy() du module copy comme le montre l’exemple suivant
On a vite fait d’enfreindre la règle 1 lorsque l’on passe des valeurs en paramètre à une fonction. Il se trouve en effet que si l’on passe en paramètre à une fonction un type de données non élémentaire et mutable tel qu’une liste, la fonction en question peut sans problème modifier le contenu de cette liste lors de son exécution:
Lors de l’appel de la fonction show(), le contenu de la liste garden a été modifié par la fonction durant son exécution. On appelle ce phénomène un effet de bord de l’appel de la fonction show() tout-à-fait similaire aux effets secondaires et indésirables d’un médicament dans le domaine pharmacologique.
|
TYPES DE DONNÉES MUTABLES ET IMMUTABLES |
Afin de réduire les risques liés aux effets de bord, les concepteurs du langage Python ont introduit une distinction entre types de données mutables et immutables. Les types de données immutables connus jusqu’à présent sont les suivants : les nombres entiers (int), les nombres flottants (float), les chaines de caractères (str), les bytes (byte) et les tuples. De ce fait, si l’on tente de modifier un caractère individuel à l’intérieur d’une chaine de caractères, le programme lève une exception
Pour corriger le contenu de la chaine de caractères s, il faut redéfinir la chaine à neuf :
Lors de ce procédé, un tout nouvel objet str est créé qui n’est aucunement lié à la précédente chaine. L’alias s pointe alors sur ce nouvel objet et l’ancien est « oublié » s’il n’est référencé par aucun autre alias. À l’interne, le ramasse-miettes de Python (Garbage Collector en anglais) supprime périodiquement les objets « défunts » ainsi oubliés lorsqu’ils ne sont plus référencés par aucun alias. |
EMPAQUETAGE ET DÉPAQUETAGE |
À première vue, les tuples ne semblent pas être très différents des listes. Ils sont en fait comme des listes immutables et supportent donc toutes les opérations présentes sur les listes qui n’en modifient pas le contenu. Il faut cependant connaître quelques détails de notation des tuples impliquant des virgules de manière spéciale. On peut omettre les parenthèses rondes lors de la création d’un tuple:
La virgule est dans ce cas utilisée comme un caractères syntaxique permettant de séparer les éléments les uns des autres. Cette technique appelée empaquetage automatique (automatic packing en anglais) peut être utilisée pour retourner plusieurs valeurs différentes sous forme de tuple depuis une fonction:
On peut également utiliser l’opérateur virgule dans la partie gauche d’une assignation dont l’expression droite retourne un tuple. On parle alors de dépaquetage automatique (automatic unpacking en anglais):
On peut par exemple utiliser cette technique pour définir rapidement plusieurs variables différentes de manière simultanée:
Dans l’exemple suivant, la première instruction effectue un empaquetage automatique dans l’expression de droite tandis que la deuxième réalise un dépaquetage automatique dans la partie gauche de l’assignation:
Notons qu’il est également possible d’utiliser la technique du dépaquetage automatique avec les listes :
Cela permet par exemple de permuter de manière élégante les valeurs de deux variables sans aucune variable supplémentaire :
|
LISTES BIDIMENSIONNELLES, MATRICES |
Les matrices sont réalisées par des tableaux dans de nombreux langages de programmation. Les lignes sont stockées sous forme de tableaux (listes) et la matrice en elle-même comme une liste de lignes, à savoir une liste de listes. Il est trivial d’utiliser des listes au lieu de tableaux en Python. Il faut cependant faire très attention au fait qu’en Python les listes ne se comportent pas comme des types de données élémentaires et immutables puisqu’elles ne font que de stocker des références sur d’autres objets et non les objets eux-mêmes. Lors de la création d’une matrice, on peut très facilement tomber dans un travers déjà rencontré et traité. Sans se douter de rien, voici comment un programmeur inattentif va générer une matrice 3x3 remplie de zéros dans la console Python.
Ce programmeur tête en l’air sera certainement surpris lorsqu’il tentera de modifier la dernière valeur de la première ligne à l’aide de l’opérateur d’affectation : il constatera en effet que la dernière valeur a changé dans toutes les lignes.
Que s’est-il donc passé ? Il vous suffit sans doute d’y réfléchir attentivement en vous rappelant ce que l’on a déjà dit sur les copies de listes. Le code précédent est en effet parfaitement équivalent au code suivant qui commence par créer une variable z:
On crée tout d’abord une liste z contenant trois zéros puis une liste A fabriquée à partir de cette même liste z répétée trois fois. Il faut cependant bien voir que ces trois listes ne sont que trois références à la même liste en mémoire. Ainsi, si l’on change l’une d’entre elles, les « autres » seront également affectées.
Pour éviter cet écueil, on peut utiliser une compréhension de liste. Comme vous pourrez le vérifier, la matrice se comporte correctement si elle est créée de la manière suivante:
|
FUNCTION DECORATORS |
En Python, il est possible « décorer » les fonctions à l’aide d’une ligne débutant par le symbole @. Une telle ligne s’appelle un décorateur et on l’utilise pour associer des propriétés spéciales à une fonction. Un décorateur est donc une fonction qui fait office d’emballage (function wrapper en anglais) pour la fonction originale qui est décorée. La fonction décorée est en général appelée au sein de la fonction décorateur. Dans le programme suivant, la fonction trisect(x) est décorée de telle manière qu’elle retourne la valeur 0 pour x = 0 et que toutes les valeurs soient arrondies à deux décimales. def tri(func): # inner function def _tri(x): if x == 0: return 0 return round(func(x), 2) return _tri @tri def trisect(x): return 3 / x for x in range(0, 11): value = trisect(x) print(value) Nous avons déjà vu dans le chapitre Chapitre 3.7 qu’il est possible de décorer des fonctions de telle manière qu’elles soient automatiquement enregistrées comme des gestionnaires d’événement sous forme de fonction de rappel. Dans le Chapitre 7.2, nous avons également utilisé le décorateur @staticmethod pour rendre les méthodes statiques. |
PROGRAMMATION FONCTIONNELLE ET MODULAIRE |
Nous avons déjà vu qu’il faut structurer un programme de manière à isoler les bouts de codes que l’on utilisera à de nombreuses reprises dans des fonctions. La plupart du temps, ces fonctions font appel à des valeurs supplémentaires que l’on peut leur fournir par des arguments ou par des variables globales. Le résultat du traitement effectué par la fonction est quant à lui retourné soit par l’intermédiaire d’une instruction return ou par une variable globale. Cependant, comme nous l’avons déjà vu dans la règle 2, le fait de modifier des variables globales depuis une fonction constitue un très mauvais style de programmation qui, en plus d’être très inélégant, est également très dangereux puisque la fonction produit alors des effets de bords, comparables aux effets secondaires indésirables des médicaments. Pour éviter ces dangers, on veillera à respecter la
Le paradigme de programmation fonctionnelle consiste à n’utiliser que des fonctions qui ne produisent pas d’effet de bord. De telles fonctions comportent de surcroît l’avantage suivant : du fait qu’elles se suffisent à elles-mêmes et n’utilisent que les valeurs passées en paramètre, elles peuvent sans problème être placées dans un fichier séparé et, de ce fait, être réutilisées dans un autre programme. Un tel fichier, regroupant différentes fonctions et classes apparentées, est appelé module. Un projet informatique un tant soit peu sérieux est normalement séparé en plusieurs modules qui peuvent parfois être développés par plusieurs personnes ou équipes différentes. Un programme bien conçu utilise donc habituellement les principes de base de la programmation modulaire. Comme les fonctions d’un module peuvent être réutilisées dans plusieurs domaines différents, on surnomme parfois les modules ou un ensemble de modules une bibliothèque de programme, ou simplement une bibliothèque. Du point de vue de l’utilisateur de la bibliothèque, les détails d’implémentation des fonctions ne sont pas importants. Le programmeur utilisateur doit uniquement être en mesure de pouvoir déterminer, à l’aide de la documentation de la bibliothèque, les noms des fonctions, la liste de paramètres qu’elles acceptent et la spécification des valeurs de retour possibles. Du fait que le fonctionnement exact des fonctions de la bibliothèque demeure caché au programmeur qui les utilise, on parle souvent de boîtes noires. [plus... Le code source d’un programme ou d’une bibliothèque n’est souvent pas Dans la mesure où l’on développe les fonctions en respectant les principes de la programmation fonctionnelle (sans effet de bord), on peut placer ces fonctions dans un fichier séparé du programme principal en les baptisant d’un nom significatif et évoquant clairement leur rôle. Pour les réutiliser depuis un autre programme, il est alors nécessaire d’importer ce module. En guise de démonstration, le programme suivant définit un module starlib.py permettant de dessiner des étoiles de différentes tailles à l’aide de la tortue. Au début du programme principal, les fonctions du module sont importées à l’aide de l’instruction from starlib import *. Si l’on ne fait que d’utiliser la fonction star du module starlib, on peut optimiser un peu l’importation en spécifiant explicitement la fonction à importer avec l’instruction from starlib import star. Cette forme d’importation spécifique est même meilleure puisqu’elle n’importera que les fonctions réellement nécessaires et utilisées.
|