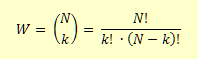![]()
INTRODUCTION |
Bien que le mot information soit utilisé très couramment, il n’est pas si facile de saisir avec précision le concept d’information en tant que grandeur mesurable. Dans la vie courante, l’information est liée à la connaissance et dire que quelqu’un dispose d’avantage d’information signifie que cette personne en sait plus sur un certain sujet qu’une personne B qui n’est pas bien informée. Pour quantifier le surplus d’information dont dispose A par rapport à B (ou à l’équipe B) ou, à l’inverse, le manque d’information de B par rapport à A, il faut imaginer un jeu de quiz télévisé. La personne ou l’équipe B doit découvrir une information que seule la personne A connaît comme par exemple sa profession. Pour ce faire, B peut poser des questions auxquelles A ne répondra que par « oui » ou « non ». Les règles sont les suivantes: Le défaut d’information I de B par rapport à A (en bits) est le nombre de questions fermées (réponse oui/non) que B doit poser à A en moyenne et avec une stratégie optimale pour disposer des mêmes connaissances que A sur le sujet en question. |
DEVINETTES DE NOMBRES |
Vous pourriez facilement imaginer un tel jeu dans votre classe ou juste dans votre esprit de la manière suivante : votre camarade Léa sort de la salle et l’un de ses W = 16 camarades de classe reçoit un objet désirable tel qu’une barre de chocolat. Lorsque Léa réintègre la salle, vous et vos camarades savez qui détient la barre de chocolat alors que Léa n’en sait rien. Comment quantifier ce manque d’information dont souffre Léa? Pour simplifier les explications, numérotons les élèves de 0 à 15. Léa peut alors poser n’importe quelle question à ses camarades dans le but de trouver le nombre secret qui lui vaudra la barre de chocolat. Son but est de poser le moins de questions possible jusqu’à pouvoir trouver de manière certaine la personne cachant la branche. Elle aurait par exemple la possibilité d’essayer successivement n’importe quel nombre aléatoirement : « est-ce le 13 ? ». Si la réponse est « non », elle reprend en demandant un autre nombre au bol.
Si le nombre secret est « 0 », il suffit alors d’une seule question. Si le nombre secret est « 1 », deux questions seront nécessaires et ainsi de suite. Si le nombre secret est « 14 », il faut alors 15 questions de même que si le nombre secret est 15 puisqu’il ne reste alors plus qu’une seule alternative. Le programme simule le jeu 100’000 fois et compte le nombre de questions nécessaires jusqu’à ce que le nombre secret soit découvert. Ces résultats sont additionnés pour en déterminer la moyenne. from random import randint sum = 0 z = 100000 repeat z: n = randint(0, 15) if n != 15: q = n + 1 # number of questions else: q = 15 sum += q print("Mean:", sum / z) En utilisant cette stratégie, Léa devrait poser en moyenne 8.43 questions, ce qui est tout de même assez important. Mais comme Léa est intelligente, elle décide d’utiliser une stratégie bien plus efficace. Elle commence par demande : « Est-ce un nombre entre 0 et 7, bornes incluses ? ». Si la réponse est « oui », elle divise les possibilités restantes en deux groupes et demande : « Est-ce un nombre entre 0 et 3 ? ». Si la réponse est à nouveau « oui », elle demande alors : « Est-ce un nombre compris entre 0 et 1 (compris) ? ». Si la réponse est à nouveau positive, elle demande : « Est-ce 0 ? ». À ce stade, elle connaîtra la réponse quelle que soit la réponse. Avec cette stratégie d’interrogation « binaire » et pour W=16, Léa trouve toujours le nombre secret en exactement quatre questions, ce qui représente donc également le nombre moyen de questions à poser. Cela montre que la stratégie de bissection est optimale et que l’information concernant la personne cachant la barre est donc quantifiée à I = 4 bits. .
|
MEMENTO |
|
Comme vous pouvez le montrer vous-mêmes, la quantité d’information pour W = 32 vaut I = 5 bits et vaudra 6 bits pour W = 64. Ainsi, 2I = Wou, autrement dit, I = ld(W). ). L’information en question n’est pas nécessairement un nombre et peut résider dans le fait de déterminer un état quelconque parmi un nombre W d’états équiprobables. Ainsi, l’information découlant de la connaissance d’un état donné parmi W états équiprobables est donnée par |
QUANTITÉ D’INFORMATION CONTENUE DANS UN MOT |
Comme les W états sont équiprobables, la probabilité de chacun des états vaut p = 1/W, ce qui permet également d’écrire l’information de la manière suivante I = ld(1/p) = -ld(p) Vous vous doutez bien que les probabilités d’occurrence de chacune des lettres de l’alphabet sont sensiblement différentes d’une langue à l’autre. Le tableau suivant montre la probabilité d’occurrence de chacune des lettres en anglais [plus... Les valeurs diffèrent dun texte à l’autre. Les probabilités indiquées ici correspondent à un texte littéraire].
Pour simplifier, supposons que la probabilité d’occurrence d’une lettre dans un mot soit indépendante des autres caractères. Bien que cette hypothèse ne soit certainement pas réaliste, elle permet de conclure que la probabilité p d’un mot de deux lettres de probabilités respectives p1 et p2 est, d’après la formule du produit, p = p1 * p2 et, concernant l’information:
ou, pour un nombre quelconque de lettres,
Le programme suivant permet de saisir un mot et d’afficher en sortie la quantité d’information contenue dans ce mot. Pour cela, il est nécessaire de télécharger les fichiers comportant la fréquence pour l’allemand, l’anglais et le français grâce à ce lien et de les copier dans le dossier où réside votre script Python. from math import log f = open("letterfreq_de.txt") s = "{" for line in f: line = line[:-1] # remove trailing \n s += line + ", " f.close() s = s[:-2] # remove trailing , s += "}" occurance = eval(s) while True: word = inputString("Enter a word") I = 0 for letter in word.upper(): p = occurance[letter] / 100 I -= log(p, 2) print(word, "-> I =", round(I, 2), "bit")
|
MEMENTO |
|
Les données sont stockées dans le fichier en question ligne à ligne au format 'lettre' : pourcentage. La structure de données Python qui se prête le mieux à représenter ces données est le dictionnaire. Le fichier est donc lu ligne à ligne et empaqueté dans une chaine de caractères au format approprié {clé : valeur, clé : valeur, ...}. Cette chaine de caractères est ensuite évaluée par l’interpréteur Python comme du Python grâce à la fonction eval() et le dictionnaire est créé. Comme vous pouvez le constater, la quantité d’information contenue dans les mots comprenant des lettres peu fréquentes est supérieure. Il faut bien noter que la quantité d’information déterminée de cette manière n’a rien à voir avec l’importance ou la pertinence subjective du mot dans un contexte donné. Autrement dit, cette mesure ne permet pas de savoir si l’information véhiculée par ce mot vous laisse complètement indifférent ou si, au contraire, elle est pour vous d’une importance cruciale. La détermination d’une telle mesure dépasse d’ailleurs largement la capacité des systèmes d’information actuels. |
EXERCICES |
|
MATÉRIEL SUPPLÉMENTAIRE |
RELATION ENTRE DÉSORDRE ET ENTROPIE |
Il existe une relation très intéressante entre l’information dont on dispose à propos d’un système et son niveau d’ordre. L’ordre dans une classe dont tous les élèves sont sagement assis à leur place est certainement bien plus élevé que s’ils sont tous en train de se déplacer de manière aléatoire dans la salle. Dans le cas de l’état désordonné, il est très difficile de connaître la position de chacun des élèves. On peut donc utiliser cette mesure de notre défaut de connaissance pour avoir une idée du niveau de désordre dans la classe. Le concept qui se cache derrière cette quantification du désordre est l’entropie.
Comme le montrent l’expérience quotidienne ainsi que la simulation ci-dessous, les systèmes qui sont abandonnés à leur propre sort ont tendance à passer d’un état ordonné à un état désordonné. Voici quelques exemples concrets :
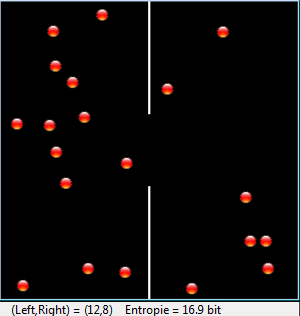
Les animations sont réalisées à l’aide du module JGameGrid. Les particules sont modélisées par la classe Particle dérivant de Actor et se déplacent grâce à leur méthode act() qui est appelée automatiquement lors de chaque cycle de simulation. Les collisions sont gérées par des événements en dérivant la classe CollisionListener de la classe GGActorCollisionListener et en redéfinissant la méthode collide(). Ce procédé est le même que celui mis en œuvre au chapitre 8.10 dans la simulation du mouvement browninien. Les 20 particules sont ensuite réparties en 4 groupes de vitesses différents. Étant donné que les vitesses sont échangées entre particules, l’énergie totale du système demeure constante, ce qui correspond à un système fermé. from gamegrid import * from gpanel import * from math import log # =================== class Particle ==================== class Particle(Actor): def __init__(self): Actor.__init__(self, "sprites/ball_0.gif") # Called when actor is added to gamegrid def reset(self): self.isLeft = True def advance(self, distance): pt = self.gameGrid.toPoint(self.getNextMoveLocation()) dir = self.getDirection() # Left/right wall if pt.x < 0 or pt.x > w: self.setDirection(180 - dir) # Top/bottom wall if pt.y < 0 or pt.y > h: self.setDirection(360 - dir) # Separation if (pt.y < h // 2 - r or pt.y > h // 2 + r) and \ pt.x > self.gameGrid.getPgWidth() // 2 - 2 and \ pt.x < self.gameGrid.getPgWidth() // 2 + 2: self.setDirection(180 - dir) self.move(distance) if self.getX() < w // 2: self.isLeft = True else: self.isLeft = False def act(self): self.advance(3) def atLeft(self): return self.isLeft # =================== class CollisionListener ========= class CollisionListener(GGActorCollisionListener): # Collision callback: just exchange direction and speed def collide(self, a, b): dir1 = a.getDirection() dir2 = b.getDirection() sd1 = a.getSlowDown() sd2 = b.getSlowDown() a.setDirection(dir2) a.setSlowDown(sd2) b.setDirection(dir1) b.setSlowDown(sd1) return 5 # Wait a moment until collision is rearmed # =================== Global sections ================= def drawSeparation(): getBg().setLineWidth(3) getBg().drawLine(w // 2, 0, w // 2, h // 2 - r) getBg().drawLine(w // 2, h, w // 2, h // 2 + r) def init(): collisionListener = CollisionListener() for i in range(nbParticles): particles[i] = Particle() # Put them at random locations, but apart of each other ok = False while not ok: ok = True loc = getRandomLocation() if loc.x > w / 2 - 20: ok = False continue for k in range(i): dx = particles[k].getLocation().x - loc.x dy = particles[k].getLocation().y - loc.y if dx * dx + dy * dy < 300: ok = False addActor(particles[i], loc, getRandomDirection()) delay(100) # Select collision area particles[i].setCollisionCircle(Point(0, 0), 8) # Select collision listener particles[i].addActorCollisionListener(collisionListener) # Set speed in groups of 5 if i < 5: particles[i].setSlowDown(2) elif i < 10: particles[i].setSlowDown(3) elif i < 15: particles[i].setSlowDown(4) # Define collision partners for i in range(nbParticles): for k in range(i + 1, nbParticles): particles[i].addCollisionActor(particles[k]) def binomial(n, k): if k < 0 or k > n: return 0 if k == 0 or k == n: return 1 k = min(k, n - k) # take advantage of symmetry c = 1 for i in range(k): c = c * (n - i) / (i + 1) return c r = 50 # Radius of hole w = 400 h = 400 nbParticles = 20 particles = [0] * nbParticles makeGPanel(Size(600, 300)) window(-6, 66, -2, 22) title("Entropy") windowPosition(600, 20) drawGrid(0, 60, 0, 20) makeGameGrid(w, h, 1, False) setSimulationPeriod(10) addStatusBar(20) drawSeparation() setTitle("Entropy") show() init() doRun() t = 0 while not isDisposed(): nbLeft = 0 for particle in particles: if particle.atLeft(): nbLeft += 1 entropy = round(log(binomial(nbParticles, nbLeft), 2), 1) setStatusText("(Left,Right) = (" + str(nbLeft) + "," + str(nbParticles-nbLeft)+ ")"+" Entropie = "+str(entropy)+" bit") if t % 60 == 0: clear() lineWidth(1) drawGrid(0, 60, 0, 20) lineWidth(3) move(0, entropy) else: draw(t % 60, entropy) t += 1 delay(1000) dispose() # GPanel
|
MEMENTO |
|
Vu de l’extérieur (d’un point de vue macroscopique), un état est déterminé par le nombre k de ses particules dans la partie droite et, de ce fait, par les N-k particules présentes dans sa partie gauche. Une observation macroscopique ignore complètement lesquelles des k particules parmi les N se trouvent dans la partie de droite. D’après les formules de l’analyse combinatoire, on a possibilités différentes. Le défaut d’information est en l’occurrence donné par
Le processus temporel est représenté graphiquement dans un graphique GPanel. On peut clairement observer que les particules se répartissent avec le temps entre les deux compartiments bien qu’il existe une infime chance que toutes les particules se retrouvent à un moment donné toutes à gauche. La probabilité de cet événement décroît cependant rapidement avec le nombre de particules présentes dans le système. La deuxième loi de la thermodynamique repose de ce fait sur une propriété statistique des systèmes comportant de nombreuses particules. Étant donné que l’on n’observe jamais le processus inverse se produire, les processus de ce type sont dits irréversibles. Il existe cependant des systèmes passant du désordre à l’ordre mais il faut pour cela une « contrainte ordonnatrice ».Some examples are: Voici quelques exemples parlants de systèmes qui passent du désordre vers l’ordre
|
EXERCICES |
|