Forum
9.2 RELATIONALE DATENBANKEN
![]()
EINFÜHRUNG |
Computersysteme sind nicht nur Rechenmaschinen, die Zahlen verarbeiten, sondern auch hervorragend geeignet, um Informationen jeglicher Art als Daten zu speichern, die gespeicherten Daten gemäss bestimmter Kriterien zu verarbeiten und die Resultate in lesbarer Form wieder auszugeben. Sie können die Daten millionenfach schneller verarbeiten als der Mensch und die Grösse der Datenspeicher ist praktisch unbegrenzt. Damit sind Computer zentrales Element der heutigen Gesellschaft geworden, in der täglich enorme Mengen von Informationen gesammelt und verarbeitet werden. Das effiziente Sammeln, Übertragen, Verarbeiten und Ausgeben grosser Mengen von Daten ist in einem eigenen modernen Fachgebiet, genannt Big Data, zusammengewachsen. Im täglichen Leben wird Information vielfach in textlicher Form festgehalten, beispielsweise "Anna Karlsson wohnt in Berlin" oder "Anna Karlsson ist Mutter von Rossi Angéla". Es gibt verschiedene Möglichkeiten, wie man solche Informationen in einem digitalen Datenspeicher ablegt, der aus einer sequentiellen Anordnung von Bytes (= 8 bits) besteht. Eine naheliegende Möglichkeit besteht darin, die Buchstaben des Texts im ASCII-Code als Bytes oder im Unicode als Doppelbytes zu speichern, wie dies in einer Textdatei gemacht wird. Es ist aber offensichtlich, dass diese Art der Datenspeicherung viel redundanten Speicherplatz benötigt, da man an der ganzen umgangssprachlichen Satzkonstruktion meist nicht interessiert ist. Zudem ist es schwierig und zeitaufwendig, grosse Datenmengen nach bestimmten Informationen zu durchsuchen. Es ist deshalb angebracht, die Daten gemäss ihren inneren Zusammenhängen zu strukturieren. Die optimale Strukturierungsart hängt allerdings stark von der Art der Informationen ab, die man speichern will. Aus dem täglichen Leben weiss man aber, dass sich viele Informationen am besten in Form von Tabellen erfassen lassen, beispielsweise einfache Personaldaten.
Andere Information sind allerdings schlecht in Tabellen zu erfassen, beispielsweise Beziehungsinformationen wie Stammbäume:
Aus diesem Grund gibt es verschiedene Datenbankmodelle. Das am weiten verbreitete ist das Relationale Datenbankmodell, wo Tabellen als Datenstruktur verwendet werden und das hervorragend geeignet ist, Informationen in verschiedenen Tabellen miteinander zu verknüpfen. Für die Manipulation der Daten wird eine spezielle Datenbanksprache SQL (Structured Query Language) verwendet, darum nennt man relationale Datenbanken auch SQL-Datenbanken [mehr...
Unter einer Datenbank versteht man gewöhnlich den Einfache Datenbanken können sich lokal auf einem PC befinden und von einer einzelnen Person verwendet werden, beispielsweise für die Verwaltung von Musik-CDs oder der Resultate einer Schulsportveranstaltung. Oft sind Datenbanken aber über das Internet für viele Benützer gleichzeitig zugänglich (Online-Datenbanken). Die Grundprinzipien, die du im Folgenden kennenlernen wirst, bleiben aber die gleichen. |
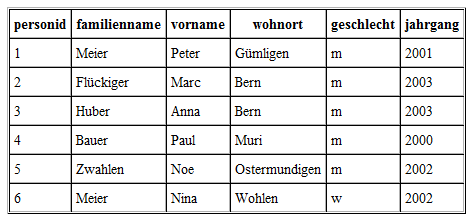
PERSONENTABELLE MIT CREATE ERZEUGEN |
Als exemplarisches Beispiel betrachtest du die Erfassung von Personendaten in einer Schule und die Verarbeitung von Sportleistungsdaten eines Schulsporttages. Dabei werden die erfassten Daten stark vereinfacht. Du verwendest hier als Datenbanksystem SQLite, das eine grosse Verbreitung auf vielen Rechnertypen hat, insbesondere auch auf mobilen Geräten. Die Personendaten speicherst du in einer Tabelle mit dem Namen person. Für jede Person gibt es einen Zeileneintrag, auch Datensatz (record) genannt. Die Spalten (auch Felder genannt) enthalten die Eigenschaften (Attribute) der Datensätze.
Das Python-Modul sqlite enthält alle Funktionen, die zur Manipulation der SQLite-Datenbank benötigt werden. Die eigentlichen Daten befinden sich in einer Datenbankdatei schule.db. Statt Datenbankdatei sagen wir oft auch nur kurz Datenbank.
Ohne zusätzliche Pfadangabe wird die Datei schule.db im Unterverzeichnis \bin des TigerJython-Installationsverzeichnisses gespeichert. Sie können aber auch den vollständigen Pfad der Datei im gewünschten Verzeichnis angeben. Wenn Sie zum Beispiel für Ihre Datenbankdateien ein Verzeichnis c:\dbEx einrichten, wird die Dtei mit dem Befehl Der Zugriff auf die Datenbank erfolgt immer nach dem gleichen Prinzip: Mit dem Aufruf von connect(dateinamen) erstellst du eine "Verbindung" zur Datenbank und erhältst dabei ein Verbindungsobjekt zurück. Falls die Datenbank noch nicht existiert, wird sie dabei erzeugt. Mit diesem Objekt führst du die Datenbankoperationen durch und zwar in einem with-Programmblock. Die Verwendung des with-Blocks hat den grossen Vorteil, dass am Ende des Blocks mit Sicherheit die Verbindung zur Datenbank automatisch wieder geschlossen wird, sogar wenn im Innern des Blocks Fehler auftreten. Zuerst forderst du mit cursor = con.cursor() einen sogenannten Datenbank-Cursor an, den du nachher für den Aufruf von SQL-Befehlen verwendest. Die Befehlssprache SQL ist in englischem Volltext verfasst und darum oft selbsterklärend. Am Ende des Kapitels findest du eine Übersicht über die wichtigsten Befehle. from sqlite3 import * with connect("schule.db") as con: cursor = con.cursor() sql = """CREATE TABLE person (personid INTEGER PRIMARY KEY, familienname VARCHAR, vorname VARCHAR, wohnort VARCHAR, geschlecht VARCHAR, jahrgang INTEGER)""" cursor.execute(sql) print("Done")
Nach der Ausführung des Programms befindet sich die Datei schule.db im gleichen Verzeichnis wie das Programm. Versuchst du, die Tabelle nochmals zu erzeugen, so ergibt sich eine Fehlermeldung und du musst die Tabelle zuerst wieder löschen. Das Löschen erfolgt mit dem SQL-Befehl DROP TABLE: from sqlite3 import * with connect("schule.db") as con: cursor = con.cursor() cursor.execute("DROP TABLE person") print("Done")
|
MEMO |
|
Zum Erstellen der Tabelle wird der SQL-Befehl CREATE TABLE verwendet. In der Klammer legst du die Tabellenstruktur fest, d.h. die Namen der Felder und deren Datentyp. Wir verwenden für die Namen den SQL-Datentyp VARCHAR. Damit lassen sich in SQLite Strings beliebiger Länge speichern. Das erste Feld personid mit der Zusatzangabe PRIMARY KEY (Primärschlüssel) ist ein wichtiges Hilfsfeld, mit dem sich jeder Datensatz mit einen eindeutigen Integer 1,2,... identifizieren lässt. Die Verwendung des Dreifach-Anführungszeichen ist praktisch, da man damit den SQL-Befehl zur besseren Übersichtlichkeit auf mehreren Zeilen verteilen kann, ohne Stringverlängerungszeichen zu benötigen. Wir verwenden die drei Anführungszeichen aber nur bei langen SQL-Befehlen. |
DATENSÄTZE MIT INSERT EINFÜGEN |
Personendaten werden üblicherweise in einem Eingabedialog aufgenommen und dann in der Datenbank eingefügt. Das Prinzip lernst du aber hier zuerst mit Personendaten kennen, die du im Programmcode fest einbaust. Die Datensätze werden mit dem INSERT-Befehl in die Datenbank übernommen, wobei du Namen und Werte der Attribute angibst. from sqlite3 import * with connect("schule.db") as con: cursor = con.cursor() sql = """INSERT INTO person (familienname, vorname, wohnort, geschlecht, jahrgang) VALUES ('Huber', 'Anna', 'Bern', 'w', 2002)""" cursor.execute(sql) print("Done")
|
MEMO |
|
Da wir das Feld personid als PRIMARY KEY ausgezeichnet haben, wird der Wert automatisch hochgezählt, ohne dass wir uns darum kümmern müssen. Da du die Daten mehrerer Personen erfassen willst, ist es zweckmässig, eine Funktion insert(person) zu definieren, in der die Personendaten als Variablen definiert sind. Die Formatierung mit den Platzhaltern %s für Strings und %d für Integers ist dabei sehr hilfreich. from sqlite3 import * def insert(a, b, c, d, e): with connect("schule.db") as con: cursor = con.cursor() sql = """INSERT INTO person (familienname, vorname, wohnort, geschlecht, jahrgang) VALUES ('%s', '%s', '%s', '%s', %d)""" %(a, b, c, d, e) cursor.execute(sql) insert('Meier', 'Peter', 'Worb', 'm', 2001) insert('Fluri', 'Marc', 'Bern', 'm', 2003) insert('Huber', 'Anna', 'Bern', 'w', 2003) insert('Bauer', 'Paul', 'Muri', 'm', 2000) insert('Zwahlen', 'Noe', 'Ostermundigen', 'm', 2002) insert('Meier', 'Nina', 'Wohlen', 'w', 2001) print("Done")
|
PERSONENDATEN MIT SELECT ANZEIGEN |
Natürlich möchtest du schon lange kontrollieren, ob sich die Daten auch tatsächlich in der Datenbank befinden. Dazu verwendest du mit SELECT den wichtigen SQL-Befehl überhaupt. Nach dessen Aufruf erhältst du die Antwort der Datenbank in einem sogenannten Resultset, auf den du mit dem Datenbank-Cursor zugreifst. Du kannst dir den Resultset wie eine sequentielle Anordnung der Rückgabewerte vorstellen, wobei der Datenbank-Cursor auf einen bestimmten Wert "zeigt". Der Aufruf cursor.fetchall() liefert dir alle Rückgabeinformation als Liste, die du in einer for-Schleife Element um Element durchlaufen und ausschreiben kannst. from sqlite3 import * con = connect("schule.db") with con: cursor = con.cursor() cursor.execute("SELECT * FROM person") result = cursor.fetchall() for person in result: print(person)
|
MEMO |
Der Stern * ist ein Wildcard und mit SELECT * wählst du alle Attribute der Datensätze aus. Du könntest die Abfrage auch auf einzelne Felder beschränken, beispielsweise auf den Familien- und Vornamen und den Wohnort: SELECT familienname, vorname, wohnort FROM TABLE person Das Modul prettytable hilft dir, Tabellendaten als String zu formatieren und im Ausgabefenster auszuschreiben. from sqlite3 import * from prettytable import printTable con = connect("schule.db") with con: cursor = con.cursor() cursor.execute("SELECT familienname, vorname, wohnort FROM person") printTable(cursor)
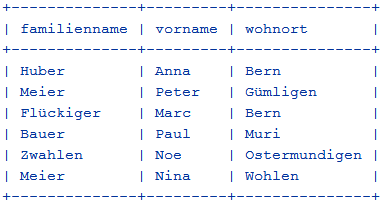
Da printTable() den Datenbank-Cursor verwendet, muss sich der Aufruf innerhalb des with-Blocks befinden. Du kannst die Personendaten auch sofort alphabetisch nach Familien- und Vorname sortiert ausschreiben: from sqlite3 import * from prettytable import printTable con = connect("schule.db") with con: cursor = con.cursor() sql = """SELECT familienname, vorname, wohnort FROM person ORDER BY familienname, vorname""" cursor.execute(sql) printTable(cursor)
Im Ausgabefenster siehst du:
|
MEMO |
Mit dem Datenbank-Browser DB Browser for SQLite, den du von www.sqlitebrowser.org herunterlädst und installierst, kannst du die Datenbank über eine grafische Benutzeroberfläche manipulieren. |
NUR BESTIMMTE DATENSÄTZE MIT WHERE AUSWÄHLEN |
Im SELECT-Befehl kannst du auch mit einer WHERE-Bedingung bestimmte Datensätze auswählen, beispielsweise erhältst du alle Personen, die in Bern wohnen, mit dem Programm: from sqlite3 import * from prettytable import printTable with connect("schule.db") as con: cursor = con.cursor() sql = """SELECT familienname, vorname, wohnort FROM person WHERE wohnort = 'Bern'""" cursor.execute(sql) printTable(cursor)
oder alle Personen mit dem Jahrgang 2002 oder später: from sqlite3 import * from prettytable import printTable with connect("schule.db") as con: cursor = con.cursor() sql = """SELECT familienname, vorname, jahrgang FROM person WHERE jahrgang >= 2002""" cursor.execute(sql) printTable(cursor)
|
MEMO |
Bedingungen kannst du auch mit logischen Operatoren verbinden, beispielsweise mit AND und OR. Sehr praktisch ist die Verwendung von sogenannten Wildcards (Platzhalter). Das Zeichen % ist ein Platzhalter für beliebig viele Buchstaben, das Zeichen _ für einen einzelnen Buchstaben. Im SELECT-Befehl verwendest du dann in der WHERE-Bedingung LIKE. Beispielsweise erhältst du alle Personen, die einen Vornamen haben, der mit P beginnt, mit |
from sqlite3 import * from prettytable import printTable with connect("schule.db") as con: cursor = con.cursor() sql = """SELECT familienname, vorname, wohnort FROM person WHERE vorname LIKE 'P%'""" cursor.execute(sql) printTable(cursor)
|
PERSONENDATEN MIT UPDATE MUTIEREN |
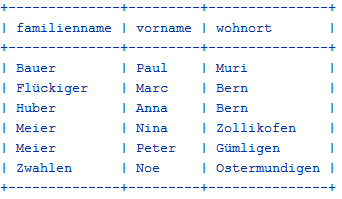
Um einen bestimmten Werte eines Datensatzes zu ändern, verwendest du den SQL-Befehl UPDATE. Dabei musst du aber sorgfältig darauf achten, dass du die WHERE-Bedingung so wählst, dass nur der gewünschte Datensatz ausgewählt wird. Zieht beispielsweise Meier Nina von Wohlen nach Zollikofen, so führst du die Mutation wie folgt durch: from sqlite3 import * from prettytable import printTable with connect("schule.db") as con: cursor = con.cursor() sql = """UPDATE person SET wohnort = 'Zollikofen' WHERE familienname = 'Meier' and vorname = 'Nina'""" cursor.execute(sql) cursor.execute("SELECT familienname, vorname, wohnort FROM person") printTable(cursor)
|
MEMO |
Beim UPDATE-Befehl musst du besonders vorsichtig sein, dass die Bedingung im WHERE nur für den Datensatz zutrifft, den du ändern willst. Vergisst du beispielsweise im vorhergehenden Beispiel den WHERE-Teil, so wohnen alle Personen nachher in Zollikofen. |
DATENSÄTZE MIT DELETE LÖSCHEN |
Willst du einen bestimmten Datensatz löschen, so verwendest du den SQL-Befehl DELETE. Auch hier musst du sehr sorgfältig darauf achten, dass du die WHERE-Bedingung so wählst, dass nur der gewünschte Datensatz ausgewählt wird. Um beispielsweise Bauer Paul aus der Datenbank zu entfernen, schreibst du: from sqlite3 import * from prettytable import printTable with connect("schule.db") as con: cursor = con.cursor() sql = """DELETE FROM person WHERE familienname = 'Bauer' and vorname = 'Paul'""" cursor.execute(sql) cursor.execute("SELECT familienname, vorname, wohnort FROM person") printTable(cursor)
|
MEMO |
Vergisst du den WHERE-Teil, so werden alle Datensätze gelöscht. Die Tabelle ist nachher zwar noch vorhanden, aber leer. Manchmal ist dies aber erwünscht und du schreibst bewusst zum Löschen aller Datensätze: from sqlite3 import * from prettytable import printTable with connect("schule.db") as con: cursor = con.cursor() cursor.execute("DELETE FROM person") cursor.execute("SELECT familienname, vorname, wohnort FROM person") printTable(cursor)
Nachdem du die Tabelle mit DROP TABLE gelöscht hast, kann du die Programme in diesem Kapitel nach eigenen Ideen modifiziert erneut durchspielen. |
|
Die wichtigsten SQL-Befehle
|
AUFGABEN |
|
ZUSATZSTOFF |
MIT DEM CURSOR DEN RESULTSET DURCHLAUFEN |
Die Werte im Resultset nach einem SELECT-Befehl kannst du auf verschiedene Arten verwenden. Mit cursor.fetchall() erhältst du eine Python-Liste, in der jede Datensatzinformation (kurz auch Datensatz genannt) in einem Tupel gespeichert ist, das Unicode-Strings für VARCHAR-Felder verwendet. from sqlite3 import * with connect("schule.db") as con: cursor = con.cursor() cursor.execute("SELECT * FROM person") result = cursor.fetchall() print(result)
Im Ausgabefenster siehst du [(1, u'Meier', u'Peter', u'G\xfcmligen', u'm', 2001), ,,,] Du kannst den Resultset aber mit cursor.fetchone() auch Datensatz um Datensatz durchlaufen. Dabei wird der Cursor bei jedem Aufruf um einen Datensatz "vorwärts gestellt". Ist er am Ende angelangt, so gibt der Aufruf None zurück. Du kannst die Datensätze also in einer while-Schleife durchlaufen und anzeigen: from sqlite3 import * with connect("schule.db") as con: cursor = con.cursor() cursor.execute("SELECT * FROM person") result = 0 while result != None: result = cursor.fetchone() print(result)
Im Ausgabefenster werden die einzelnen Datensätze als Tupels ausgeschrieben. Selten wird auch der Aufruf cursor.fetchmany(n) verwendet, der die n folgenden Datensätze in einer Liste liefert. Dabei wird der Cursor um n Datensätze vorwärts gestellt. Wird dabei das Ende erreicht, so werden nur die noch vorhandenen Datensätze geliefert und ein weiterer Aufruf liefert eine leere Liste. Im folgenden Programm holst du immer zwei Datensätze miteinander. from sqlite3 import * with connect("schule.db") as con: cursor = con.cursor() cursor.execute("SELECT * FROM person") result = None while result != []: result = cursor.fetchmany(2) print(result)
|
MEMO |
Es ist wichtig zu wissen, dass bei jedem Aufruf von fetchone(), fetchmany() und fetchall() der Datenbank-Cursor vorwärts gestellt wird. Ein zweiter Aufruf bezieht sich also nur noch auf den Rest der Datensätze. Wird beispielsweise fetchall() ein zweites Mal aufgerufen, so wird eine leere Liste zurückgegeben. In SQLite kann man den Resultset nur vorwärts durchlaufen, in vielen anderen Datenbanken aber vorwärts und rückwärts. |
DATENBANKINFORMATONEN HOLEN |
|
Der Aufruf von showTables() gibt dir in einer Liste alle Tabellennamen der Datenbank zurück und mit describeTable(table) ermittelst du die Tabellenstruktur einer Tabelle. from sqlite3 import * with connect("schule.db") as con: tables = con.showTables() for table in tables: print("\nTable:", table) print(con.describeTable(table))
|
RESULTSET IN EINEM EIGENSTÄNDIGEN FENSTER ANZEIGEN |
Du kannst mit dem Modul prettytable den ganzen Resultset auch in einem eigenständigen Fenster anzeigen. Dazu brauchst du nur printTable(cursor) durch showTable(cursor) zu ersetzen (Textausrichtungsparameter sind allerdings unwirksam). from sqlite3 import * from prettytable import * with connect("schule.db") as con: cursor = con.cursor() cursor.execute("SELECT * FROM person") showTable(cursor)
|