6.2 CLIENT-SERVER-MODELL, HTTP
![]()
EINFÜHRUNG |
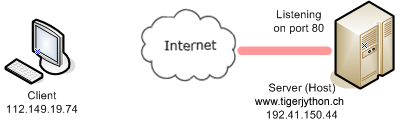
Du weisst bereits, dass eine Webseite, die in deinem Web-Browser angezeigt wird, durch eine gewöhnliche HTML-Textdatei beschrieben ist, die sich in der Regel auf einem Internet-Server (auch Host genannt) befindet. Um die Datei zu lokalisieren, verwendet der Browser die URL in der Form http://servername/dateipfad. http steht hier für Hypertext Transfer Protocol und bezeichnet das Verfahren, wie die Datei vom Server zu deinem Browser-PC, auch Client genannt, transferiert wird. Der Servername, auch IP-Adresse (IP: Internet Protocol) genannt, ist entweder in der "gepunkteten" Form, z.B. 192.41.150.141, oder als Alias, z.B. www.tigerjython.com. Der Dateipfad der HTML-Datei beginnt mit einem Bruchstrich, ist aber auf dem Server relativ zu einem bestimmten Dokumentenpfad. Bei der Kommunikation zwischen dem Client und dem Server wir das Request-Respond-Verfahren eingesetzt, eines der wichtigsten Prinzipien der Rechnerkommunikation. Dabei wird davon ausgegangen, dass auf dem Server ein Serverprogramm gestartet ist, das auf einem bestimmten TCP-Port (für das Web Port 80) auf einen Client-Request wartet.
|
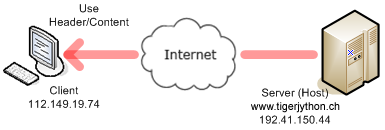
MIT HTTP EINE WEBSEITE ANFORDERN |
|
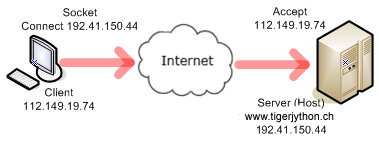
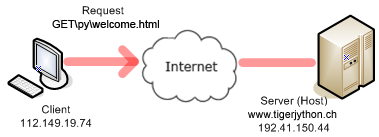
Dein Client-Programm führt die Phasen 1, 2, und 4 durch und holt dabei die Datei welcomex.html, die sich im Unterverzeichnis py des Server-Dokumentenpfads befindet. Die Methode socket() der socket-Klasse, liefert in der Variablen s ein Socket-Objekt. Dabei müssen zwei Konstanten übergeben werden, die den richtigen Socket-Typ festlegen. import socket host = "www.tigerjython.ch" port = 80 # Phase 1 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((host , port)) # Phase 2 request = "GET /py/welcome.html HTTP/1.1\r\nHost: " + host + "\r\n\r\n" s.sendall(request) # Phase 4 reply = s.recv(4096) print("\nReply:\n") print(reply) |
MEMO |
|
Der Request, um eine Webseite von einem Webserver anzufordern, verwendet das HTTP-Protokoll. Dies ist eine Vereinbarung zwischen Client und Server und legt in allen Einzelheiten den Ablauf des Datentransfers fest. Der GET-Befehl ist im HTTP wie folgt dokumentiert [mehr... Internet-Protokolle werden in sogenannten RFC (Request for Comments) beschrieben, HTTP im RFC 2616 ]:
|
HTTPS VERWENDEN |
|
Immer mehr Websites verwenden an Stelle von HTTP das HTTPS-Protokoll, bei dem die Daten mittels SSL (Secure Socket Layer) verschlüsselt werden. Bei einem solchen Server kann ein HTTP-Request auf Port 80 zu einer Fehlermeldung führen, wie beim folgenden Programm für den Server github.com: import socket host = "www.github.com" port = 80 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((host , port)) request = "GET /py/welcome.html HTTP/1.1\r\nHost: " + host + "\r\n\r\n" s.sendall(request) reply = s.recv(4096) print("\nReply:\n") print(reply) Die Antwort ist: HTTP/1.1 301 Moved Permanently Content-length: 0 Location: https://www.github.com/py/welcome.html Es ist aber sehr einfach, den Request in HTTPS zu ändern. Dazu muss der Port auf 443 gesetzt werden und eine Zeile mit ssl.wrap_socket() eingefügt werden: import socket import ssl host = "github.com" port = 443 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((host , port)) s = ssl.wrap_socket(s) request = "GET / HTTP/1.1\r\nHost: " + host + "\r\n\r\n" s.sendall(request) reply = s.recv(4096) print("\nReply:\n") print(reply) |
HTTP-HEADER UND CONNECT |
|
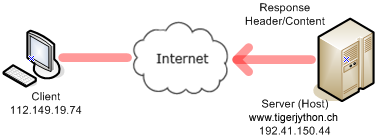
Der Response besteht aus einem Kopf (Header) mit Statusangaben und dem Inhalt (Content) mit der angeforderten Datei. Um die Webseite darzustellen, schneidest du den Kopf weg und übergibst den Inhalt einer HtmlPane. import socket from ch.aplu.util import HtmlPane host = "www.tigerjython.ch" port = 80 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((host , port)) request = "GET /py/welcome.html HTTP/1.1\r\nHost: " + host + "\r\n\r\n" s.sendall(request) reply = s.recv(4096) index = reply.find("<html") html = reply[index:] pane = HtmlPane() pane.insertText(html) |
MEMO |
|
Die Funktion recv(4096) liefert maximal 4096 Zeichen aus einem Datenbuffer, in den die empfangenen Zeichen kopiert werden. Um den Kopf wegzuschneiden, verwendest du die String-Methode find(str), welche im String nach dem übergebenen Teilstring str sucht und den Index des ersten Vorkommens zurückgibt. (Falls der Teilstring nicht vorkommt, wird -1 zurückgegeben.) Nachher kannst du mit einer Slice-Operation elegant den Teilstring, der beim Index beginnt und bis zum Ende geht, herausfiltern. |
LESEN DER WETTERPROGNOSEN |
|
Du wirst dich fragen, warum man ein so kompliziertes Verfahren anwenden soll, um eine Webseite anzuzeigen, wenn man dasselbe doch mit einer einzigen Zeile insertUrl() von HtmlPane erledigen kann. Was du eben gelernt hast, macht aber durchaus Sinn, wenn du beispielsweise den Inhalt der Webseite gar nicht in einem Browserfenster darstellen möchtest, sondern du dich lediglich für gewisse darin eingebettete Informationen interessierst. Als sinnvolle Anwendung holt dein Programm aus der Webseite von Meteo-Schweiz die aktuelle Wetterprognose und schreibt sie als Text aus. Du kannst dir das Programmierer-Leben doch etwas einfacher machen, wenn du statt der socket-Klasse die Bibliothek urllib2 heranziehst, um die Datei vom Webserver zu holen. [mehr...
Eine Bibliothek legt oft eine anwendungsgerechte vereinfachende Schicht über komplizierteren Um herauszufinden, wo sich die gewünschte Information befindet, stellst du in einem Analyseprogramm die Seite als Text im Konsole-Fenster und gleichzeitig als Webseite in deinem Standard-Browser dar. import urllib2 from ch.aplu.util import HtmlPane url = "http://www.meteonews.ch/de" HtmlPane.browse(url) html = urllib2.urlopen(url).read() print(html) |
MEMO |
|
Die Verwendung von Software-Bibliotheken wie urllib2 vereinfacht den Programmcode, verdeckt aber grundlegende Mechanismen. |
PARSEN EINES TEXTS |
|
Du hast jetzt die interessante und anspruchsvolle Aufgabe, die relevante Information aus einem langen Textstring herauszuholen, man spricht auch vom Parsen eines Texts. Als erstens stellst du dir die Teilaufgabe, mit der Funktion remove_html_tags() alle HTML-Tags aus dem String zu entfernen. Das Vorgehen ist typisch und der dabei angewendete Algorithmus kann wie folgt beschrieben werden: Du durchläufst den Text Zeichen-um-Zeichen. Dabei stellst du dir vor, dass du dir zwei Zustände merkst: Du bist ausserhalb oder innerhalb eines HTML-Tags. Nur wenn du ausserhalb eines HTML-Tags bist, kopierst du das Zeichen ans Ende eines Ausgabestrings. Der Zustandswechsel erfolgt beim Lesen der Tag-Spitzklammern < bzw. > [mehr... Der Algorithmus versagt, wenn sich innerhalb eines Tags das Zeichen > befindet]. Um die Information zu extrahieren, solltest du den ganzen Text nach der Entfernung der HTML-Tags in einen Texteditor kopieren und ihn untersuchen. Dabei suchst du nach einem Token, welches den Beginn der Information kennzeichnet. Mit der String-Methode find() kannst du den Index start dieses Tokens bestimmen. Nun suchst du beginnend bei start nach einem Token für das Ende der Information und bestimmst seinen Index end. Für diese Website handelt es sich für start um das Token "Allgemeine Lage" und für end um das Token "AutorIn". Die dazwischen liegende Information extrahierst du mit einer Slice-Operation [start:end]. import urllib2 def remove_html_tags(s): inTag = False out = "" for c in s: if c == '<': inTag = True elif c == '>': inTag = False elif not inTag: out = out + c return out def replace_umlaute(s): di = {"\xC3\xA4" : "ä", "\xC3\xB6" : "ö", "\xC3\xBC" : "ü", "\xC3\x84" : "Ä", "\xC3\x96" : "Ö", "\xC3\x9C" : "Ü", "xC3\x9F" : "ss"} for key in di: s = s.replace(key, di[key]) return s url = "http://meteonews.ch/de/" html = urllib2.urlopen(url).read() html = remove_html_tags(html) html = replace_umlaute(html) start = html.find("Allgemeine Lage") end = html.find("AutorIn") html = html[start:end].strip() print html |
MEMO |
|
Beim Parsen von Texten wird dieser gewöhnlich zeichenweise durchlaufen. In vielen Fällen helfen aber auch Methoden der String-Klasse [mehr... Fortgeschrittene Programmierer setzen oft die Theorie der Regulären Ausdrücke (Regex) ein ]. Spezialzeichen (Umlaute, usw.) werden leider unterschiedlich codiert. In HTML folgender Code verwendet.
Immer häufiger wird aber die Codierung UTF-8 verwendet, bei der Spezialzeichen mit 2 oder 3 Bytes gemäss folgender Tabelle codiert sind:
In der Umwandlungsfunktion replace_umlaute() wird von dieser Codierung ausgegangen |

SPRACHSYNTHESE DER WETTERPROGNOSEN |
|
Mit deinen Kenntnissen aus dem Kapitel Sound, kannst du den Text der Wetterprognose mit ein paar zusätzlichen Zeilen durch eine synthetische Stimme vorlesen lassen. Du fügst einfach im Programm die folgenden Zeilen an: from soundsystem import * initTTS() selectVoice("german-man") sound = generateVoice(html) openSoundPlayer(sound) play() |
AUFGABEN |
|