Forum
8.6 KORRELATION, REGRESSION
![]()
EINFÜHRUNG |
|
In den Naturwissenschaften, aber auch im täglichen Lebens spielt die Erfassung von Daten in Form von Messgrössen eine wichtige Rolle. Dabei braucht aber nicht immer ein Messinstrument zum Einsatz zu kommen. Es kann sich beispielsweise auch um Umfragewerte im Zusammenhang mit einer statistischen Untersuchung handeln. Nach der Datenerfassung geht es meist darum, die Messwerte zu interpretieren. Es kann sich um qualitative Aussagen handeln, beispielsweise dass die Messwerte im Laufe der Zeit ansteigen oder absinken, aber auch um die experimentelle Überprüfung eines Naturgesetzes. Ein grosses Problem besteht darin, dass Messungen fast immer Schwankungen ausgesetzt und nicht exakt reproduzierbar sind. Trotz dieses "Messfehlern" möchte man wissenschaftlich korrekte Aussagen machen können. Die Messfehler entstehen dabei nicht immer wegen mangelhaften Messgeräten, sondern können in der Natur des Experiments liegen. So liefert die "Messung" der Augenzahl eines geworfenen Würfels grundsätzlich streuende Werte zwischen 1 und 6. Bei jeder Art von Messung spielen darum statistische Überlegungen eine zentrale Rolle. Oft werden in einer Messserie zwei Grössen x und y miteinander gemessen und man stellt sich die Frage, ob diese in einem Zusammenhang stehen und einer Gesetzmässigkeit unterworfen sind. Trägt man die (x, y)-Werte als Messpunkte in ein Koordinatensystem ein, so spricht man von Datenvisualisierung. Fast immer erkennt man bei blosser Betrachtung der Verteilung der Messwerte, ob die Daten in einer gegenseitigen Abhängigkeit stehen.
|
UNABHÄNGIGE UND ABHÄNGIGE DATEN VISUALISIEREN |
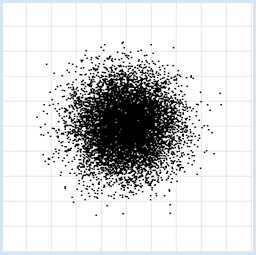
from random import random from gpanel import * z = 10000 makeGPanel(-1, 11, -1, 11) title("Uuniformly distributed value pairs") drawGrid(10, 10, "gray") xval = [0] * z yval = [0] * z for i in range(z): xval[i] = 10 * random() yval[i] = 10 * random() move(xval[i], yval[i]) fillCircle(0.03)
from random import gauss from gpanel import * z = 10000 makeGPanel(-1, 11, -1, 11) title("Normally distributed value pairs") drawGrid(10, 10, "gray") xval = [0] * z yval = [0] * z for i in range(z): xval[i] = gauss(5, 1) yval[i] = gauss(5, 1) move(xval[i], yval[i]) fillCircle(0.03)
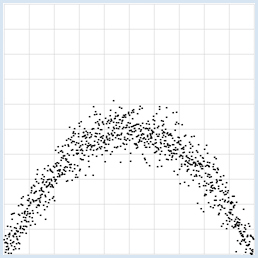
from random import gauss from gpanel import * import math z = 1000 a = 0.2 b = 2 def f(x): y = -x * (a * x - b) return y makeGPanel(-1, 11, -1, 11) title("y = -x * (0.2 * x - 2) with normally distributed noise") drawGrid(0, 10, 0, 10, "gray") xval = [0] * z yval = [0] * z for i in range(z): x = i / 100 xval[i] = x yval[i] = f(x) + gauss(0, 0.5) move(xval[i], yval[i]) fillCircle(0.03)
|

MEMO |
|
Durch Datenvisualisierung erkennt man gegenseitige Abhängigkeiten von Messgrössen auf den ersten Blick [mehr... Dieses Beispiel ist dadurch berühmt, weil die unten eingeführte Korrelation die Abhängigkeit nicht erkennt]. Bei im Intervall [a, b] gleichverteilten Zufallszahlen kommen die Zahlen in jedem gleichlangen Teilintervall mit gleicher Häufigkeit vor. Normalverteilte Zahlen haben eine glöckenförmige Verteilung, wobei 68% der Zahlen im Intervall (Mittelwert - Streuung) und (Mittelwert + Streuung) liegen. |
KOVARIANZ ALS MASSZAHL FÜR ABHÄNGIGKEITEN |
Da x und y unabhängig, gilt für die Wahrscheinlichkeit pxy, beim Doppelwurf das Paar x, y zu erhalten pxy = px * py. Die Vermutung liegt nahe, dass allgemein die folgende Produktregel gilt. Sind x und y unabhängig, so ist der Erwartungswert von x*y gleich dem Produkt der Erwartungswerte von x und y [mehr...
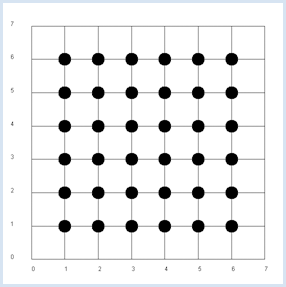
Der theoretische Beweis ist einfach: In der Simulation wird diese Vermutung bestätigt. from random import randint from gpanel import * z = 10000 # number of double rolls def dec2(x): return str(round(x, 2)) def mean(xval): n = len(xval) count = 0 for i in range(n): count += xval[i] return count / n makeGPanel(-1, 8, -1, 8) title("Double rolls. Independent random variables") addStatusBar(30) drawGrid(0, 7, 0, 7, 7, 7, "gray") xval = [0] * z yval = [0] * z xyval = [0] * z for i in range(z): a = randint(1, 6) b = randint(1, 6) xval[i] = a yval[i] = b xyval[i] = xval[i] * yval[i] move(xval[i], yval[i]) fillCircle(0.2) xm = mean(xval) ym = mean(yval) xym = mean(xyval) setStatusText("E(x) = " + dec2(xm) + \ ", E(y) = " + dec2(ym) + \ ", E(x, y) = " + dec2(xym))
|
MEMO |
|
Es ist zweckmässig, eine Statusbar zu verwenden, um die Resultate auszuschreiben. Die Funktion dec2() rundet die Werte auf 2 Stellen und gibt sie als String ab. Die Werte unterliegen natürlich einer statistischen Schwankung. In der nächsten Simulation untersuchst du nicht mehr die geworfenen Augenpaare, sondern die Augenzahl x des ersten Würfels und die Summe y der beiden Augenzahlen. Es ist offensichtlich, dass nun y in einer Abhängigkeit von x ist, denn wenn beispielsweise x = 1 ist, so ist die Wahrscheinlichkeit für y = 4 nicht dieselbe wie wenn x = 2 ist. |
from random import randint from gpanel import * z = 10000 # number of double rolls def dec2(x): return str(round(x, 2)) def mean(xval): n = len(xval) count = 0 for i in range(n): count += xval[i] return count / n def covariance(xval, yval): n = len(xval) xm = mean(xval) ym = mean(yval) cxy = 0 for i in range(n): cxy += (xval[i] - xm) * (yval[i] - ym) return cxy / n makeGPanel(-1, 11, -2, 14) title("Double rolls. Independent random variables") addStatusBar(30) drawGrid(0, 10, 0, 13, 10, 13, "gray") xval = [0] * z yval = [0] * z xyval = [0] * z for i in range(z): a = randint(1, 6) b = randint(1, 6) xval[i] = a yval[i] = a + b xyval[i] = xval[i] * yval[i] move(xval[i], yval[i]) fillCircle(0.2) xm = mean(xval) ym = mean(yval) xym = mean(xyval) c = xym - xm * ym setStatusText("E(x) = " + dec2(xm) + \ ", E(y) = " + dec2(ym) + \ ", E(x, y) = " + dec2(xym) + \ ", c = " + dec2(c) + \ ", covariance = " + dec2(covariance(xval, yval))) |
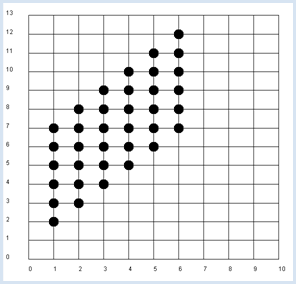
MEMO |
|
Du erhältst in der Simulation für die Kovarianz den Wert von ungefähr 2.9. Die Kovarianz eignet sich also sehr wohl als Mass für die Abhängigkeit von Zufallsvariablen. |
DER KORRELATIONSKOEFFIZIENT |
Die eben eingeführte Kovarianz hat noch einen Nachteil. Je nachdem wie die Messgrössen x und y skaliert sind, ergeben sich andere Werte, auch wenn die Werte offenbar gleichermassen voneinander abhängig sind. Du kannst dies leicht einsehen. Nimmst du beispielsweise zwei Würfel, die statt der Augenzahlen 1, 2,...,6 die Augenzahlen 10, 20,...,60 haben, so ändert sich die Kovarianz stark, obschon die Abhängigkeit dieselbe ist. Aus diesem Grund hat führt man eine normierte Kovarianz ein, die man Korrelationskoeffizient nennt, indem man die Kovarianz durch die Streuungen der x und y-Werte dividiert:
Der Korrelationskoeffizient bleibt immer im Bereich -1 bis 1. Ein Wert nahe bei 0 entspricht einer kleinen Abhängigkeit, ein Wert nahe bei 1 einer grossen Abhängigkeit, wobei zunehmende Werte von x zunehmenden Werte von y entsprechen, für einen Wert nahe bei -1 entsprechen zunehmende Werte von x abnehmenden Werten von y. Im Programm verwendest du wieder den Doppelwurf und untersuchst die Abhängigkeit der Summe der Augenzahlen von der Augenzahl des ersten Würfels.
from random import randint from gpanel import * import math z = 10000 # number of double rolls k = 10 # scalefactor def dec2(x): return str(round(x, 2)) def mean(xval): n = len(xval) count = 0 for i in range(n): count += xval[i] return count / n def covariance(xval, yval): n = len(xval) xm = mean(xval) ym = mean(yval) cxy = 0 for i in range(n): cxy += (xval[i] - xm) * (yval[i] - ym) return cxy / n def deviation(xval): n = len(xval) xm = mean(xval) sx = 0 for i in range(n): sx += (xval[i] - xm) * (xval[i] - xm) sx = math.sqrt(sx / n) return sx def correlation(xval, yval): return covariance(xval, yval) / (deviation(xval) * deviation(yval)) makeGPanel(-1 * k, 11 * k, -2 * k, 14 * k) title("Double rolls. Independent random variables.") addStatusBar(30) drawGrid(0, 10 * k, 0, 13 * k, 10, 13, "gray") xval = [0] * z yval = [0] * z xyval = [0] * z for i in range(z): a = k * randint(1, 6) b = k * randint(1, 6) xval[i] = a yval[i] = a + b xyval[i] = xval[i] * yval[i] move(xval[i], yval[i]) fillCircle(0.2 * k) xm = mean(xval) ym = mean(yval) xym = mean(xyval) c = xym - xm * ym setStatusText("E(x) = " + dec2(xm) + \ ", E(y) = " + dec2(ym) + \ ", E(x, y) = " + dec2(xym) + \ ", covariance = " + dec2(covariance(xval, yval)) + \ ", correlation = " + dec2(correlation(xval, yval)))
|
MEMO |
|
Du kannst den Skalenfaktor k verändern und der Korrelationskoeffzient bleibt immer ungefähr 0.71, hingegen ändert sich die Kovarianz stark [mehr...
Der Korrelationskoeffizient prüft eigentlich nur lineare Abhängigkeiten. Wendest du ihn beispielsweise Statt Korrelationskoeffizient sagt man auch nur kurz Korrelation. |
MEDIZINWISSENSCHAFTLICHE PUBLIKATION |
Nobelpreise: Schokoladekonsum: Du willst die Untersuchung selbst nachvollziehen. In deinem Programm verwendest du für den Ländernamen, den Schokoladekonsum in kg pro Jahr und Einwohner und die Zahl der Nobelpreisträger pro 10 Millionen Einwohner eine Liste data mit Teillisten aus drei Elementen. Im Programm stellst du die Daten grafisch dar und bestimmst den Korrelationskoeffizienten. from gpanel import * import math data = [["Australia", 4.8, 5.141], ["Austria", 8.7, 24.720], ["Belgium", 5.7, 9.005], ["Canada", 3.9, 6.253], ["Denmark", 8.2, 24.915], ["Finland", 6.8, 7.371], ["France", 6.6, 9.177], ["Germany", 11.6, 12.572], ["Greece", 2.5, 1.797], ["Italy", 4.1, 3.279], ["Ireland", 8.8, 12.967], ["Netherlands", 4.5, 11.337], ["Norway", 9.2, 21.614], ["Poland", 2.7, 3.140], ["Portugal", 2.7, 1.885], ["Spain", 3.2, 1.705], ["Sweden", 6.2, 30.300], ["Switzerland", 11.9, 30.949], ["United Kingdom", 9.8, 19.165], ["United States", 5.3, 10.811]] def dec2(x): return str(round(x, 2)) def mean(xval): n = len(xval) count = 0 for i in range(n): count += xval[i] return count / n def covariance(xval, yval): n = len(xval) xm = mean(xval) ym = mean(yval) cxy = 0 for i in range(n): cxy += (xval[i] - xm) * (yval[i] - ym) return cxy / n def deviation(xval): n = len(xval) xm = mean(xval) sx = 0 for i in range(n): sx += (xval[i] - xm) * (xval[i] - xm) sx = math.sqrt(sx / n) return sx def correlation(xval, yval): return covariance(xval, yval) / (deviation(xval) * deviation(yval)) makeGPanel(-2, 17, -5, 55) drawGrid(0, 15, 0, 50, "lightgray") xval = [] yval = [] for country in data: d = country[1] v = country[2] xval.append(d) yval.append(v) move(d, v) fillCircle(0.2) text(country[0]) title("Chocolate-Brainpower-Correlation: " + dec2(correlation(xval, yval)))
|
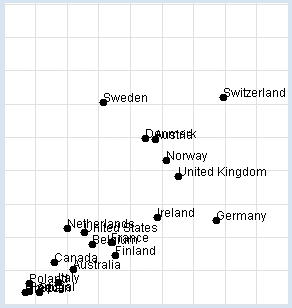
MEMO |
|
Es ergibt sich eine hohe Korrelation von ungefähr 0.71, die man auf verschiedene Arten interpretieren kann. Richtig ist es zu sagen, dass es einen Zusammenhang zwischen den beiden Datenreihen gibt, allerdings lässt sich über den Grund nur spekulieren. Insbesondere ist damit ein kausaler Zusammenhang zwischen Schokoladekonsum und Intelligenz keineswegs nachgewiesen. Grundsätzlich gilt: Bei einer hohen Korrelation zwischen x und y kann die Grösse x die Ursache für das Verhalten von y sein. Ebenso kann die Grösse y die Ursache für das Verhalten von x sein, oder x und y mit anderen gemeinsamen, vielleicht sogar unbekannten Ursachen im Zusammenhang stehen. Diskutiere Sinn und Zweck dieser Untersuchung auch mit Personen aus deinem Umfeld und frage sie nach ihrer Meinung. |
MESSFEHLER UND RAUSCHEN |
from random import gauss from gpanel import * import math z = 1000 a = 0.6 b = 2 sigma = 1 def f(x): y = a * x + b return y def dec2(x): return str(round(x, 2)) def mean(xval): n = len(xval) count = 0 for i in range(n): count += xval[i] return count / n def covariance(xval, yval): n = len(xval) xm = mean(xval) ym = mean(yval) cxy = 0 for i in range(n): cxy += (xval[i] - xm) * (yval[i] - ym) return cxy / n def deviation(xval): n = len(xval) xm = mean(xval) sx = 0 for i in range(n): sx += (xval[i] - xm) * (xval[i] - xm) sx = math.sqrt(sx / n) return sx def correlation(xval, yval): return covariance(xval, yval) / (deviation(xval) * deviation(yval)) makeGPanel(-1, 11, -1, 11) title("y = 0.6 * x + 2 normally distributed measurement errors") addStatusBar(30) drawGrid(0, 10, 0, 10, "gray") setColor("blue") lineWidth(3) line(0, f(0), 10, f(10)) xval = [0] * z yval = [0] * z setColor("black") for i in range(z): x = i / 100 xval[i] = x yval[i] = f(x) + gauss(0, sigma) move(xval[i], yval[i]) fillCircle(0.03) xm = mean(xval) ym = mean(yval) move(xm, ym) circle(0.5) setStatusText("E(x) = " + dec2(xm) + \ ", E(y) = " + dec2(ym) + \ ", correlation = " + dec2(correlation(xval, yval))) |
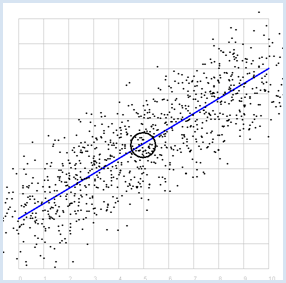
MEMO |
|
Es ergibt sich erwartungsgemäss eine hohe Korrelation, die umso grösser wird, je kleiner die Streuung sigma der Messwerte gewählt wird. Für sigma = 0 ist die Korrelation exakt 1. |
REGRESSIONSGERADE, BESTER FIT |
Vorher bist du von einer Geraden ausgegangen, die du "verrauscht" hast. Hier stellst du dir die umgekehrte Frage: Wie findest du die Gerade wieder heraus, wenn du nur die beiden Messreihen hast? Die gesuchte Gerade nennst du Regressionsgerade. Immerhin weisst du schon, dass die Regressionsgerade durch den Punkt P mit den Erwartungswerten geht. Um sie zu finden, gehst du wie folgt vor:
from random import gauss from gpanel import * import math z = 1000 a = 0.6 b = 2 def f(x): y = a * x + b return y def dec2(x): return str(round(x, 2)) def mean(xval): n = len(xval) count = 0 for i in range(n): count += xval[i] return count / n def covariance(xval, yval): n = len(xval) xm = mean(xval) ym = mean(yval) cxy = 0 for i in range(n): cxy += (xval[i] - xm) * (yval[i] - ym) return cxy / n def deviation(xval): n = len(xval) xm = mean(xval) sx = 0 for i in range(n): sx += (xval[i] - xm) * (xval[i] - xm) sx = math.sqrt(sx / n) return sx sigma = 1 makeGPanel(-1, 11, -1, 11) title("Simulate data points. Press a key...") addStatusBar(30) drawGrid(0, 10, 0, 10, "gray") setStatusText("Press any key") xval = [0] * z yval = [0] * z for i in range(z): x = i / 100 xval[i] = x yval[i] = f(x) + gauss(0, sigma) move(xval[i], yval[i]) fillCircle(0.03) getKeyWait() xm = mean(xval) ym = mean(yval) move(xm, ym) lineWidth(3) circle(0.5) def g(x): y = m * (x - xm) + ym return y def errorSum(): count = 0 for i in range(z): x = i / 100 count += (yval[i] - g(x)) * (yval[i] - g(x)) return count m = 0 setColor("red") lineWidth(1) error_min = 0 while m < 5: line(0, g(0), 10, g(10)) if m == 0: error_min = errorSum() else: if errorSum() < error_min: error_min = errorSum() else: break m += 0.01 title("Regression line found") setColor("blue") lineWidth(3) line(0, g(0), 10, g(10)) setStatusText("Found slope: " + dec2(m) + \ ", Theory: " + dec2(covariance(xval, yval) /(deviation(xval) * deviation(xval)))) |
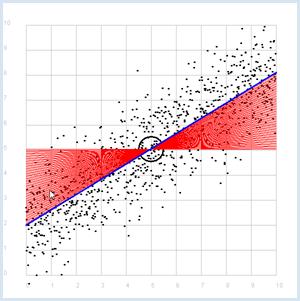
MEMO |
|
Statt den besten Fit mit einer Computersimulation zu finden, kannst du ihre Steigung auch mit
berechnen. Da die Regressionsgerade durch den Punkt P mit den Erwartungswerten E(x) und E(y) geht, besitzt sie also die Geradengleichung:
|
AUFGABEN |
|
ZUSATZSTOFF |
MIT AUTOKORRELATION VERSTECKTE INFORMATION FINDEN |
Intelligente Wesen auf einem weit entfernten Planeten möchten Kontakt mit anderen Lebewesen aufnehmen. Sie senden dazu Radiosignale aus, die eine bestimmte Regelmässigkeit aufweisen (du kannst dir darunter eine Art Morsesignale vorstellen). Auf dem langen Übertragungsweg wird das Signal immer schwächer und immer mehr von statistisch schwankendem Rauschen überdeckt. Empfangen wir dieses Signal auf der Erde mit einem Radioteleskop, so hören wir vorerst nur das Rauschen. Die Statistik und ein Computerprogramm kann uns aber helfen, das ursprünglich Radiosignal wieder herauszuholen. Wenn du nämlich den Korrelationskoeffizienten des Signals mit seinem eigenen zeitverschobenen Signal berechnest, so verringern sich die statistischen Rauschanteile. (Eine Korrelation mit sich selbst nennt man Autokorrelation).
from random import gauss from gpanel import * import math def mean(xval): n = len(xval) count = 0 for i in range(n): count += xval[i] return count / n def covariance(xval, yval): n = len(xval) xm = mean(xval) ym = mean(yval) cxy = 0 for i in range(n): cxy += (xval[i] - xm) * (yval[i] - ym) return cxy / n def deviation(xval): n = len(xval) xm = mean(xval) sx = 0 for i in range(n): sx += (xval[i] - xm) * (xval[i] - xm) sx = math.sqrt(sx / n) return sx def correlation(xval, yval): return covariance(xval, yval)/(deviation(xval)*deviation(yval)) def shift(offset): signal1 = [0] * 1000 for i in range(1000): signal1[i] = signal[(i + offset) % 1000] return signal1 makeGPanel(-10, 110, -2.4, 2.4) title("Noisy signal. Press a key...") drawGrid(0, 100, -2, 2.0, "lightgray") t = 0 dt = 0.1 signal = [0] * 1000 while t < 100: y = 0.1 * math.sin(t) # Pure signal # noise = 0 noise = gauss(0, 0.2) z = y + noise if t == 0: move(t, z + 1) else: draw(t, z + 1) signal[int(10 * t)] = z t += dt getKeyWait() title("Signal after autocorrelation") for di in range(1, 1000): y = correlation(signal, shift(di)) if di == 1: move(di / 10, y - 1) else: draw(di / 10, y - 1) Programmcode markieren
Noch erlebnisreicher ist es, zuerst das verrauschte Signal und dann das daraus extrahierte Nutzsignal anzuhören. Dazu verwendest du dein Wissen aus dem Kapitel Sound.
from soundsystem import * import math from random import gauss from gpanel import * n = 5000 def mean(xval): count = 0 for i in range(n): count += xval[i] return count / n def covariance(xval, k): cxy = 0 for i in range(n): cxy += (xval[i] - xm) * (xval[(i + k) % n] - xm) return cxy / n def deviation(xval): xm = mean(xval) sx = 0 for i in range(n): sx += (xval[i] - xm) * (xval[i] - xm) sx = math.sqrt(sx / n) return sx makeGPanel(-100, 1100, -11000, 11000) drawGrid(0, 1000, -10000, 10000) title("Press <SPACE> to repeat. Any other key to continue.") signal = [] for i in range(5000): value = int(200 * (math.sin(6.28 / 20 * i) + gauss(0, 4))) signal.append(value) if i == 0: move(i, value + 5000) elif i <= 1000: draw(i, value + 5000) ch = 32 while ch == 32: openMonoPlayer(signal, 5000) play() ch = getKeyCodeWait() title("Autocorrelation running. Please wait...") signal1 = [] xm = mean(signal) sigma = deviation(signal) q = 20000 / (sigma * sigma) for di in range(1, 5000): value = int(q * covariance(signal, di)) signal1.append(value) title("Autocorrelation Done. Press any key to repeat.") for i in range(1, 1000): if i == 1: move(i, signal1[i] - 5000) else: draw(i, signal1[i] - 5000) while True: openMonoPlayer(signal1, 5000) play() getKeyCodeWait() Programmcode markieren
|
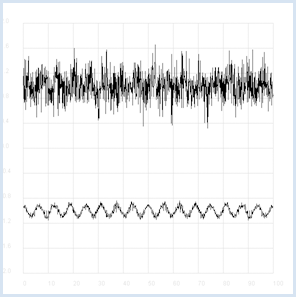
MEMO |
|
Statt das Programm auszuführen, kannst du die beiden Signale auch als WAV-Datei anhören: Rauschsignal (hier klicken)
Nutzsignal (hier klicken)
|