4.4 SPRACHSYNTHESE
![]()
EINFÜHRUNG |
Bei der Sprachsynthese wird die menschliche Stimme durch den Computer erzeugt. Ein Text-To-Speech-System (TTS) wandelt dabei geschriebenen Text in eine Sprachausgabe um. Die maschinelle Erzeugung der menschlichen Sprache ist kompliziert, aber es wurden in den letzten Jahren grosse Fortschritte erzielt. Gegenüber der Wiedergabe von vorgefertigten Sprachaufnahmen hat eine TTS den Vorteil, sehr flexibel beliebige Texte zu sprechen. Die Sprachsynthese ist Teil der Computerlinguistik. Bei der Entwicklung eines TTS ist darum eine enge Zusammenarbeit zwischen Sprachwissenschaftlern und Informatiker notwendig. Die in TigerJython eingesetzte Sprachsynthese-Software heisst MaryTTS und wurde in der Fachrichtung "Allgemeine Linguistik" der Universität des Saarlandes in Deutschland entwickelt. Das System verwendet grosse Bibliotheksdateien, die du separat von hier herunterlädst und auspackst. Im Verzeichnis, in dem sich tigerjython2.jar befindet, erstellst du dann das Unterverzeichnis Lib (falls es noch nicht vorhanden ist) und kopierst die ausgepackten Dateien hinein. |
EINEN TEXT IN 4 SPRACHEN SPRECHEN |
|
MaryTTS stellt dir in der vorliegenden Version mehrere Stimmen in den Sprachen deutsch, französisch, englisch und italienisch zur Verfügung. Du wählst die Stimme mit der Funktion selectVoice() aus. Den zu sprechenden Text übergibst du danach der Funktion generateVoice(), welche eine Liste mit den erzeugten Soundsamples zurückgibt, die du mit einem SoundPlayer abspielen kannst. from soundsystem import * initTTS() selectVoice("german-man") #selectVoice("german-woman") #selectVoice("english-man") #selectVoice("english-woman") #selectVoice("french-woman") #selectVoice("french-man") #selectVoice("italian-woman") text = "Danke dass du mir eine Sprache gibst. Viel Spass beim Programmieren" #text = "Thank you to give me a voice. Enjoy programming" #text = "Merci pour me donner une voix. Profitez de la programmation" #text = "Grazie che tu mi dia una lingua. Godere della programmazione" voice = generateVoice(text) openSoundPlayer(voice) play()
|
MEMO |
|
Die auskommentieren Zeilen kannst du verändern, um den Text von den verschiedenen Stimmen sprechen zu lassen. Du musst immer zuerst initTTS() aufrufen, um die Sprachsynthese-Software bereit zu stellen. Du könntest der Funktion initTTS() als Parameter noch einen Pfad auf das Verzeichnis mit den MaryTTS-Dateien übergeben, standardmässig handelt es sich um das Unterverzeichnis Lib. |
DAS HEUTIGE DATUM UND DIE AKTUELLE ZEIT ANKÜNDIGEN |
|
Die Anwendungen der Sprachsynthese sind vielfältig. Menschen mit Sehbehinderungen können sich Texte vorlesen lassen, Navigationssysteme und Bahnhof- oder Zugsdurchsagen verwenden oft ebenfalls synthetisch erzeugte Stimmen. Viele interaktive Computergames setzen ebenfalls künstlich erzeugte Stimmen ein. Dein Programm ermittelt aus dem Computersystem die aktuelle Zeit und liest sie mit einer deutsch- oder englischsprechenden Stimme vor. from soundsystem import * import datetime language = "german" #language = "english" #language = "french" initTTS() if language == "german": selectVoice("german-woman") month = ["Januar", "Februar", "März", "April", "Mai", "Juni", "Juli", "August", "September", "Oktober", "November", "Dezember"] if language == "english": selectVoice("english-man") month = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"] if language == "french": selectVoice("french-man") month = ["Janvier", "Février", "Mars", "Avril", "Mai", "Juin", "Juillet", "Aout", "Septembre", "Octobre", "Novembre", "Décembre"] now = datetime.datetime.now() if language == "german": text = "Heute ist der " + str(now.day) + ". " \ + month[now.month - 1] + " " + str(now.year) + ".\n" \ + "Die genaue Zeit ist " + str(now.hour) + " Uhr " + str(now.minute) if language == "english": text = "Today we have " + month[now.month - 1] + " " \ + str(now.day) + ", "+ str(now.year) + ".\n" \ + "The time is " + str(now.hour) + " hours " + str(now.minute) \ + " minutes." if language == "french": text = "Nous sommes le " + str(now.day) + " " \ + month[now.month - 1] + " " + str(now.year) + ".\n" \ + "Il est exactement " + str(now.hour) + " heures " \ + str(now.minute) + " minutes." print(text) voice = generateVoice(text) openSoundPlayer(voice) play()
|
MEMO |
|
Durch Auswahl der auskommentierten Zeile kannst du zwischen dem deutschen oder englischen Sprecher unterscheiden. Die Klasse datetime.datetime.now() liefert dir mit ihren Attributen year, month, day, hour, minute, second, microsecond die Information über das aktuelle Datum und die aktuelle Zeit. Wie du siehst, kann man bei der Definition von langen Strings den Rückwärtsbruchstrich (Backslash) als Zeilenverlängerung verwenden. |
EINE GRAFISCHE BENUTZEROBERFLÄCHE VERWENDEN |
|
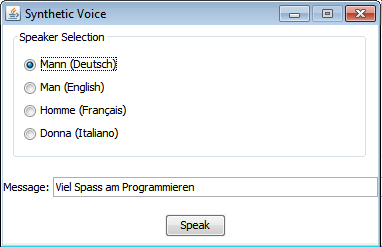
Wie du im Kapitel 3.13 bereits gelernt hast, stellt dir TigerJython Werkzeuge zur Verfügung, mit denen du einfache Benutzeroberflächen (GUIs) mit wenig Aufwand erstellen kannst. Dabei werden die klassischen Bedienungselemente wie Textfelder, Schaltflächen (Buttons), Markierungsfelder (Checkboxen), Optionsfelder (Radiobuttons) und Schieberegler (Sliders) als Objekte modelliert, die sich in Bereichen (Panes) eines Bildschirmfensters befinden, das während der Programmausführung ständig sichtbar bleibt. (Du kannst dich in der APLU-Dokumentation genauer orientieren.) In deinem Programm wird der Sprecher mit Radiobuttons ausgewählt und beim Klick auf den Bestätigungsbutton der Text im Textfeld in eine Sprachausgabe umwandelt.
from soundsystem import * from entrydialog import * speaker1 = RadioEntry("Mann (Deutsch)") speaker1.setValue(True) speaker2 = RadioEntry("Man (English)") speaker3 = RadioEntry("Homme (Français)") speaker4 = RadioEntry("Donna (Italiano)") pane1 = EntryPane("Speaker Selection", speaker1, speaker2, speaker3, speaker4) textEntry = StringEntry("Message:", "Viel Spass am Programmieren") pane2 = EntryPane(textEntry) okButton = ButtonEntry("Speak") pane3 = EntryPane(okButton) dlg = EntryDialog(pane1, pane2, pane3) dlg.setTitle("Synthetic Voice") initTTS() while not dlg.isDisposed(): if speaker1.isTouched(): textEntry.setValue("Viel Spass am Programmieren") elif speaker2.isTouched(): textEntry.setValue("Enjoy programming") elif speaker3.isTouched(): textEntry.setValue("Profitez de la programmation") elif speaker4.isTouched(): textEntry.setValue("Godere della programmazione") if okButton.isTouched(): if speaker1.getValue(): selectVoice("german-man") text = textEntry.getValue() elif speaker2.getValue(): selectVoice("english-man") text = textEntry.getValue() elif speaker3.getValue(): selectVoice("french-man") text = textEntry.getValue() elif speaker4.getValue(): selectVoice("italian-woman") text = textEntry.getValue() if text != "": voice = generateVoice(text) openSoundPlayer(voice) play()
|
MEMO |
|
Die while-Schleife wird solange durchlaufen, bis das Dialogfenster mit dem Close-Button der Titelzeile geschlossen wird. Bei jedem Durchlauf prüfst du mit isTouched(), ob seit dem letzten Aufruf der Button gedrückt wurde. Ist dies der Fall, so holst du mit getValue() die aktuellen Werte der GUI-Elemente und machst daraus wie in den vorhergehenden Programmen eine Sprachausgabe. Es ist etwas gefährlich, eine solche "enge" while-Schleife zu durchlaufen, da man damit unnötig Rechenzeit verschwendet. Allerdings wird beim Aufruf von isTouched() das Programm automatisch kurz (1ms) angehalten, damit der Durchlauf etwas gebremst wird. |
AUFGABEN |
|